Some Thoughts on Vague Language, Plausible Deniability, and the Interpretive Layer UXR Refuses to Own (And Two Ideas That Might Help: The Delta and Vibedesigning)

This is a long one. Get comfortable.
There is a chart from Willems, Albers, and Smeets (2020), and it maps probability phrases to their numerical interpretations across hundreds of respondents. "Likely" has a mean of 75%. Sounds clear enough. Except the 5th-to-95th percentile range runs from 57% to 91%. "Probable" sits at 67%, ranging from 41% to 86%. "Possible" hits 47%, ranging from 22% to 70%.
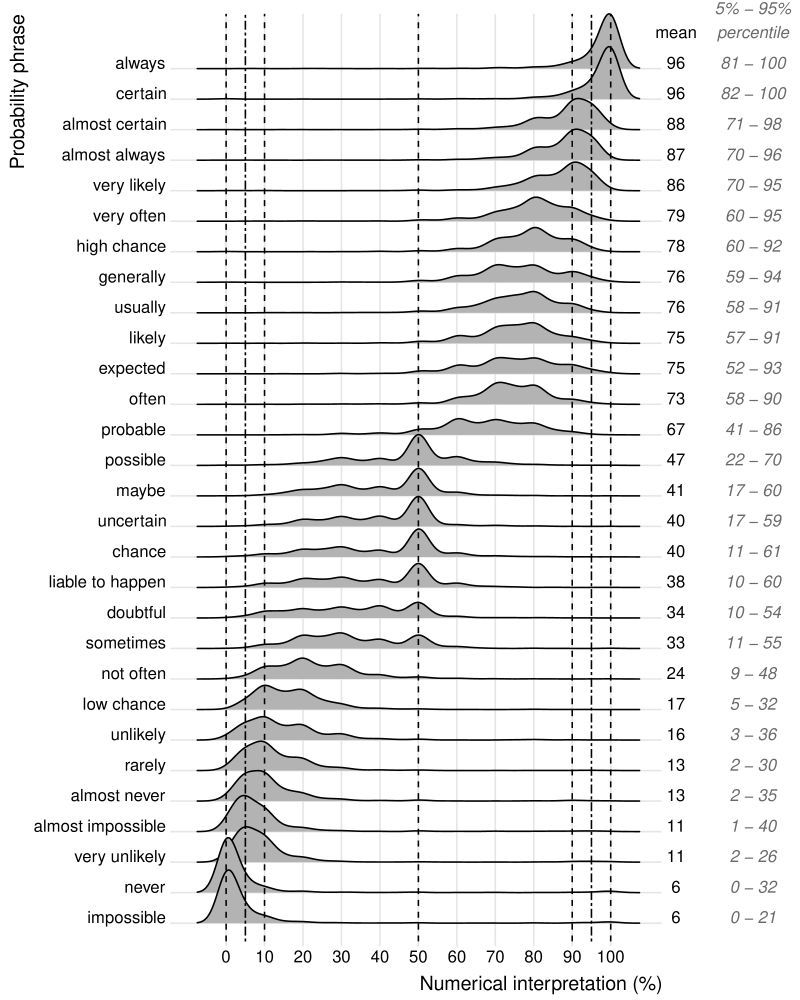
Three words. Massive overlap. For a meaningful chunk of any audience, they are functionally interchangeable.
And UXR readouts are full of them.
"Users will likely encounter friction." "This is probably a pain point." "The feature is unlikely to be discovered organically." Every one of these sentences means something different to every person in the room, and nobody asks for clarification because the vagueness feels like precision. It sounds like the researcher did the work and formed a judgment. It sounds like a finding.
It is a word where a finding should be.
What You Would Say If You Were Being Specific
The alternative is not complicated. "Nine of twelve participants failed to complete checkout without assistance." That is specific. It is also uncomfortable in ways that "users will likely struggle" is not, and I think that discomfort is the whole story.
When you say "nine of twelve," the first question from the room is "only twelve?" When you say "likely," nobody asks anything. The word moves the conversation forward without anyone having to interrogate the evidence underneath it. It functions less like a finding and more like a hallway pass.
I have sat in readouts where a researcher said "users generally preferred option A" and watched one stakeholder walk away thinking 80% and another thinking 55%. Both confident. Neither asked. Three months later someone pulls up the slide in a strategy review and discovers the team has been building on different assumptions. That meeting is never pleasant.
The Slide That Makes It Worse
The readout template is a structural enabler of this problem and nobody treats it as one.
Most research decks have a "Key Findings" section that encourages declarative one-liners. The format compresses nuance into assertion by design. "Users struggle with checkout" fits a slide. "Nine of twelve participants in a moderated study with a convenience sample failed to complete checkout, though four of those nine recovered on retry" does not. So the finding gets trimmed to fit the container, and the container was built for visual clarity, not for epistemic honesty.
The recommendation slide is worse. "Consider reducing cognitive load in the onboarding flow." "Explore opportunities to surface social proof earlier in the funnel." "Revisit the information hierarchy on the pricing page." These are real recommendations from real readouts. They commit to nothing. They specify no threshold for success. They define no failure mode. They are unfalsifiable suggestions dressed up in the visual language of expert judgment.
The slide format rewards brevity and punishes precision. The researcher who writes the careful, bounded, honest version of the finding gets told the deck is too dense. The researcher who writes "likely" gets praised for clear communication. The incentive structure of the artifact itself pushes toward the vague word.
Why This Keeps Happening
The easy explanation is that researchers are not trained in precise communication. That is true in some cases but it is mostly wrong. Most researchers know exactly what they saw. They choose the vague word anyway. And I think the reason is more strategic than anyone in the profession wants to admit.
Vague language is a form of plausible deniability.
If you say "nine of twelve failed" and the team ships anyway and it works, nobody remembers your specificity. If it fails, someone pulls up your slide and asks why the team shipped against an explicit finding. You are now the person who warned them and got ignored, which sounds good until you realize that being right and ignored is not a career accelerator at most companies.
But if you said "likely" instead of "nine of twelve," you have cover. You never technically said it would fail. You said it was likely. The word gives you an exit. It was directional. It was a signal. You flagged it.
I think most researchers do this without fully naming it. It does not feel like a strategic choice. It feels like being appropriately careful about not overstating qualitative findings. And that framing is not wrong. Small-sample qual is directional. Hedging is methodologically appropriate. But there is a difference between hedging because you respect the limits of your data and hedging because specificity makes you a target. Most readouts contain both and the researcher does not distinguish between them, even internally.
The Other Side of the Table
Researchers are not the only ones who benefit from the vagueness. The stakeholders are complicit.
A PM who receives "users generally preferred option A" gets to interpret that however supports the decision they were already leaning toward. If they want to ship option A, "generally preferred" means 80%. If they want to ship option B for strategic reasons, "generally preferred" means 55% and that is close enough to call it a wash. The vague word is a tool the PM can pick up and use in either direction. A specific number is harder to bend.
Designers do the same thing. "Users found the layout confusing" is flexible enough to justify a full redesign or a minor tweak, depending on what the designer was already planning to do. "Eleven of fifteen participants could not locate the primary action within ten seconds" is a specific problem with a specific bar for improvement. That specificity constrains the design response. Some designers welcome that. Many do not.
The vagueness serves everyone in the room. The researcher avoids being the person who "blocked the launch." The PM avoids being the person who "ignored the research." The designer avoids being constrained by a number they did not choose. The interpretive hot potato keeps moving and nobody holds it when it explodes.
This is collaborative avoidance of precision. The whole system is participating. Treating it as a researcher communication problem misses the mechanism entirely.
The Interpretive Layer Nobody Wants
The vagueness problem is part of something bigger. UXR has a deeply ingrained habit of handing off the interpretive layer.
Here is how it typically works. The researcher surfaces findings. "We heard X. We observed Y. Here is what users said and did." Then design and product take those findings and decide what they mean for the roadmap. The researcher might offer recommendations, but in most orgs the actual interpretation, the "so what do we do with this," lands on someone else's desk.
That handoff is where accountability transfers.
If the PM takes the findings and ships something that works, the PM gets credit for a good product decision informed by research. If the PM takes the findings and ships something that flops, the researcher can say they surfaced the signal. Either way the researcher is not on the hook for the outcome. The interpretive layer sits between the research and the decision, and whoever owns it owns the result.
Most UXR teams do not own it. And I think that is both the smartest and the most damaging thing the profession has done to itself.
The Shield That Is Also an Invisibility Cloak
Not owning the interpretation protects you. It means you cannot be blamed for a bad product decision. You surfaced the data. What someone did with it is their problem. In an environment where researchers are already under scrutiny, where headcount is always being questioned, where the value of qualitative work is perpetually on trial, that protection is real and it matters.
But here is the cost.
If you never own the interpretation, you never own the outcome. If you never own the outcome, you cannot show impact. If you cannot show impact, you cannot justify headcount. And when layoffs come, nobody can point to a single product decision and say "research made that happen" with 100% certainty because research was specifically designed to not be traceable to decisions.
I keep coming back to this. The same behavior that protects individual researchers from accountability is what makes entire research teams dispensable at the organizational level. The shield and the invisibility cloak are the same thing. You do not get one without the other.
Every researcher who has survived a layoff round has felt both sides of this. The relief that nobody could pin a failed launch on their findings. And the sinking awareness that nobody could pin a successful launch on them either.
The Performance Review Paradox
This connects to something that does not get discussed enough. Researchers get evaluated on "influence" and "impact." Those are the words that show up in leveling rubrics and performance criteria at most large tech companies. Demonstrate influence on product direction. Show measurable impact of research on outcomes.
But the interpretive handoff makes both of those untraceable.
You cannot claim influence on a decision you specifically positioned yourself to not own. You cannot demonstrate impact when the connection between your finding and the product outcome passes through two layers of translation by other people. The evaluation framework asks you to show something the operating model was designed to make invisible.
So researchers do what anyone would do in that situation. They perform influence. The readout becomes theater. The deck gets polished until it looks important. The video clips get curated to make leadership emotional. The recommendations get phrased to sound strategic without committing to anything specific. The quarterly review lists studies completed and stakeholder satisfaction scores, because those are the things that are measurable inside the event model, even though they have almost no correlation with whether research actually changed a decision.
I do not blame anyone for this. It is a rational response to an irrational evaluation structure. But it is worth naming because it explains why the vagueness persists even when individual researchers know it is a problem. The system rewards it.
The Directional Problem
And then there is the thing that makes all of this worse. All research is signal. All of it. Twelve interviews is a signal. Fifteen usability sessions is a signal. But so is an A/B test with a p-value of 0.04. So is a survey with n=500. So is an analytics dashboard showing a drop in conversion.
Very little research in UXR deals in definitives. Almost none. What we have is a spectrum of confidence. Some signals are high confidence. Consistent patterns across a well-recruited sample, triangulated across methods, replicated over time. Some signals are barely better than casino odds. A survey with a 6% response rate and no control for self-selection bias. An A/B test that hit significance on day three and got called early. A five-person guerrilla test run in the lobby of the building where the team works. These are all "data." They sit on very different parts of the confidence spectrum, and the organization treats most of them identically once they land in a deck.
The difference is that quant comes with visible uncertainty markers. Confidence intervals. Margins of error. P-values. These things communicate "I am a signal, here is how much you should trust me" in a language the organization recognizes as legitimate. Qual has no equivalent convention. There is no standard notation for "this came from twelve people and I believe it because the pattern was consistent and the reasoning was clear." So qual gets treated as the weaker signal even when the actual insight is sharper than anything the dashboard could tell you.
Nobody in the room says any of this.
The researcher does not say it because admitting the research is directional sounds like admitting it is weak. Nobody walks out of an A/B test readout and says "well, that was directional." They say "statistically significant." The confidence interval is right there. It has a number. The qual researcher has the same level of evidence about a different kind of question and no comparable way to package it. So qualifying your confidence feels like handing ammunition to the person who thinks you should have just run an A/B test. Even though the A/B test would not have told you why.
The PM does not say it because they want to use the research to justify a decision they were leaning toward anyway. "Research says users struggle with checkout" is a better sentence in a strategy doc than "twelve people in a moderated study had trouble, which may or may not generalize."
So directional findings circulate as facts. Owned by nobody. Questioned by nobody. Until something breaks and suddenly everyone remembers the research was "just directional." The finding gets promoted on the way in and demoted on the way out, and the researcher absorbs the cost both times. The quant finding with a barely significant p-value rarely gets the same treatment. It had a number. Numbers survive organizational memory differently than observations do, even when the number was barely better than flipping a coin.
Maybe I'm being too cynical about this. Plenty of teams handle the directional framing honestly and still make good decisions. But the packaging gap between qual and quant confidence is a bigger driver of how research gets weighted than anyone wants to admit. And the uncomfortable truth underneath all of it is that almost nothing we produce in UXR, qual or quant, is definitive. We are all working in signal. Some of us just have better gift wrapping.
The Repository Compounds the Problem
Vague findings do not stay in one readout. They migrate into the repository. And once they are there, they stack.
A "likely" from 2022 sits next to a "likely" from 2024. There is no way to compare the confidence behind them. There is no metadata about what "likely" meant in context, how many participants the finding was based on, or whether the product has changed enough that the finding no longer applies. The repository treats both as equivalent knowledge. A PM searching for prior research on checkout friction finds both and reads them as a consistent body of evidence supporting the same conclusion. They might support opposite conclusions. There is no way to tell from the words.
I have written about research expiration dates before and this is the same problem from a different angle. Findings decay. Vague findings decay invisibly because there is no precision to lose. A specific finding ages in a way you can evaluate. "Nine of twelve failed on the October 2023 version of the checkout flow" is clearly anchored to a moment. "Users likely struggle with checkout" could have been written yesterday or three years ago and it reads the same.
The repository becomes a graveyard of reasonable-sounding assertions with no provenance, no confidence interval, and no expiration date. Teams cite it with confidence. The confidence is misplaced. But the vagueness makes that invisible.
The Delta: Naming the Gap
I have been developing a concept I call the Delta. The idea is structurally simple. Instead of a researcher producing a finding and handing it to the product team to interpret, the Delta forces the researcher to name the gap between what the organization currently believes about its users and what the evidence actually supports.
A finding says: "Users in the lapsed segment don't engage with stacked offers because they find the value proposition confusing."
A Delta starts somewhere different. The organization currently operates on the assumption that lapsed users ignore stacked offers because of notification fatigue. The PM believes this. The strategy doc says this. It was probably true at some point, or at least plausible enough that nobody questioned it. The study found something different: the issue is value accumulation confusion, not fatigue. Users do not understand how offers stack, not that they are tired of seeing them.
That distance between belief and evidence is the Delta. Not the finding. The gap.
In practice, a Delta can be as simple as a table that you drop into a planning doc or a readout slide. Four columns.
| Organizational Assumption | What the Evidence Says | The Gap | Confidence |
|---|---|---|---|
| Lapsed users ignore stacked offers because of notification fatigue | 15/20 participants described confusion about how offer values accumulate. Zero mentioned fatigue unprompted. | The org is treating this as a volume problem (fewer notifications). The evidence points to a comprehension problem (clearer value stacking). These require different experiments. | High. Consistent pattern, unprompted, across segments. |
| Users in this segment are price-sensitive | 11/20 participants compared total value across offers, not individual offer price. 3 abandoned because they could not calculate the combined discount. | The segment may be value-sensitive rather than price-sensitive. The distinction changes whether you lead with discount size or total savings. | Moderate. Strong pattern but single study, recommend validation with analytics on redemption behavior. |
| Power users don't need onboarding for new features | 8/12 power users discovered the feature but misunderstood what it did. High confidence, low accuracy. | Power users don't need help finding things. They need help understanding things. The current assumption skips the wrong step. | Moderate. Small sample, but the confidence-accuracy split was consistent enough to act on directionally. |
The first column is the hard one. It requires the researcher to articulate what the organization currently believes, which is almost never written down anywhere. It lives in the PM's head, or in a strategy doc from last year, or in something a VP said in a planning meeting that everyone absorbed as truth. Surfacing that assumption is half the work and most of the value.
The second column is what researchers already do. This is the finding. The evidence. The thing the readout was built around anyway.
The third column is where the Delta actually lives. Not "here is what we found" but "here is what it means that the org was wrong in this specific direction, and here is how it changes what we should do." This is the interpretive ownership that most readouts skip. It is also the column that makes plausible deniability structurally harder to maintain, because the researcher has taken a position on what the gap means.
The fourth column is subjective. I want to be upfront about that. There is no formula for whether a finding is high or moderate or low confidence. It is the researcher's judgment call based on sample size, pattern consistency, method limitations, and how much triangulation exists. That subjectivity is the point. The researcher is the person in the room most qualified to assess how much weight a finding should carry, and the Delta asks them to do that explicitly instead of hiding behind "likely." A PM can disagree with the confidence assessment. That is a productive conversation. It is a much better conversation than the one where nobody knows how much weight to give a finding because the researcher never said.
This matters for the vagueness problem because the Delta format makes vague language structurally harder to use. You cannot write a Delta with "likely." The Delta asks: what does the org believe, what does the evidence say, and how far apart are they. Those questions require specificity. "The org believes X and the evidence shows X is likely wrong" is not a Delta. "The org believes notification fatigue drives disengagement but fifteen of twenty participants described confusion about value accumulation with no mention of fatigue" is.
The Delta also shifts where the interpretive layer sits. In the readout model, the researcher presents findings and the PM interprets them. In the Delta model, the researcher has already done the interpretive work by naming the assumption and measuring the distance. The PM does not have to translate. The translation happened in the Delta. What the PM has to do is decide whether to act on it, which is a product decision, not a research translation problem.
And it requires the researcher to take a position. To say "the assumption is wrong" or "the assumption holds but with caveats." That is the interpretive ownership that most UXR teams have been avoiding. The Delta does not let you avoid it. Which is exactly why it would help with the impact problem, and exactly why it feels dangerous.
Vibedesigning: From Words to Artifacts
There is another angle on this that I have been thinking about, and it connects to something happening in the tooling space right now.
The Figma MCP server launched its write-to-canvas capability earlier this year. The short version: AI agents can now create and modify real design assets in Figma using your organization's actual design system. The agent reads your library first and builds with what already exists. The output is not a generic mockup. It is a prototype that uses your real buttons, your real spacing, your real type scale.
Here is why this matters for the vagueness problem.
When a researcher writes as a UXD recommendation "consider reducing cognitive load in the onboarding flow," that recommendation passes through the interpretive layer. The designer reads it, imagines what "reducing cognitive load" means, and translates it into a design direction that may or may not reflect what the evidence actually suggested. The researcher's intent gets filtered through the designer's interpretation of a vague phrase. If the designer was in the readout and paying attention, the translation might be close. If they were not, or if they were but three weeks have passed, the translation drifts.
Now imagine the researcher does something different. Instead of writing a vague recommendation on a slide, they take the evidence from the study and use the Figma MCP to prototype what the finding suggests the flow should look like. Not a polished design. A rough artifact that says: based on what we observed, here is one version of what reducing that friction could look like in our actual product, using our actual design system.
You cannot prototype "likely." You cannot prototype "consider." You can only prototype a specific flow with specific screens and specific interactions. How many options does the user see? Three or seven? Is the discount shown as a percentage or a dollar amount? Does the stacked value appear before or after the user taps into the offer? Where does the CTA sit relative to the price? The moment you open a design tool, these questions become mandatory. A slide that says "explore opportunities to surface social proof earlier in the funnel" does not have to answer any of them. A prototype does. Every single one. The tooling forces the specificity that the slide format was designed to avoid, down to the level of "how many" and "in what order" and "next to what."
I think of this as vibedesigning. The same way vibecoding lets researchers build disposable micro-tools for project execution without needing to be engineers, vibedesigning lets researchers produce rough design artifacts without needing to be designers. The Figma MCP handles the design system compliance. The researcher handles the intent. The output is a concrete artifact that a designer can react to, critique, and improve, instead of a vague phrase that a designer has to interpret from scratch.
This changes the handoff. The designer is no longer translating a word into a concept. They are evaluating a concept that already exists as a rough prototype. "I see what you were going for, but the spacing is wrong and the hierarchy should be reversed" is a fundamentally different conversation than "what did you mean by cognitive load." The first conversation is productive. The second one is the interpretive hot potato.
I want to be careful about overselling this. A researcher-generated prototype is still directional. It is one interpretation of the evidence, made concrete. The designer might disagree with it completely, and they might be right. The prototype is not a recommendation. It is a conversation starter that happens to be in the medium the designer already works in, rather than in the medium the researcher works in.
But that shift in medium matters more than it might seem. Research findings communicated in words get interpreted through the lens of whoever reads the words. Research findings communicated as a rough prototype in the org's own design language get evaluated as a design artifact. The first invites projection. The second invites critique. Critique is more useful.
There are real limitations. The Figma MCP is still in beta. Not every org has a design system mature enough for the agent to work with effectively. Researchers would need at minimum a working familiarity with Figma. And there is a legitimate question about whether researchers producing design artifacts creates territorial tension with designers who see prototyping as their domain. I think the answer depends entirely on the team and the framing. A researcher who shows up with a polished prototype and says "build this" is going to create conflict. A researcher who shows up with a rough prototype and says "this is what the evidence suggests, what do you think" is starting a collaboration.
Maybe this is too optimistic. I am not entirely sure the tooling is mature enough for this to work reliably in practice right now. But the direction is clear. The gap between research finding and design artifact is getting narrower, and the tools that close it are getting easier to use. At some point, the question of whether researchers should use them stops being theoretical.
Where This Leaves Things
The vagueness in UXR readouts is not a writing problem. It is an accountability problem that has been optimized for equilibrium. Researchers benefit from it. Stakeholders benefit from it. The slide template reinforces it. The performance review rewards it. The repository preserves it. Everyone in the system has a reason to keep the words vague and nobody has a strong enough incentive to make them specific.
The Delta attacks the problem from the language side. It forces you to name the assumption, name the evidence, and name the distance between them. That specificity makes plausible deniability harder to maintain and impact easier to trace. It also requires the researcher to own the interpretation, which is the part of this that most people will find uncomfortable.
Vibedesigning attacks the problem from the output side. It replaces the vague recommendation with a concrete artifact in the medium the design team already works in. You cannot prototype ambiguity. The tool forces clarity by changing the format of the output.
Neither of these solves the underlying question of whether organizations are safe enough for researchers to be specific. That is the part I do not have an answer for. The researcher who writes a Delta and shows up with a prototype is more exposed than the researcher who writes "likely" on a slide and lets the room interpret it. If the organization punishes that exposure, the rational move is still the vague word.
I think the profession has to pick which problem it wants. The safety of vagueness or the visibility of specificity. Right now it is trying to have both and the result is a function that is protected from blame and invisible to impact measurement simultaneously.
I am not sure most organizations are ready for that conversation. I am also not sure the profession can afford to keep avoiding it.
🎯 If this resonated, subscribe to The Voice of User. One essay a week. No fluff. No spam. Just the things the rest of the field is too polite to say out loud.